2.3 Julia 想实现什么?
NOTE: 本节将详细解释是什么使 Julia 成为一门出色的编程语言。 如果这对你来说太过技术性,你可以跳过这节并前往 Section 4 学习如何使用
DataFrames.jl处理表格数据。
Julia 编程语言 (Bezanson et al., 2017) 是一门较新的语言,第一版发布于 2012 年,其目标是 简单且快速。 即,“ 运行起来像C8, 但阅读起来像 Python”(Perkel, 2019)。 它是为科学计算设计的,能够处理 大规模的数据与计算 。但仍可以相当 容易地创建和操作原型代码。
Julia 的创始人在一篇2012 年的博客 中解释了为什么要创造 Julia。 他们说9:
我们很贪婪:我们想要更多。 我们想要一门采用自由许可证的开源语言。 我们想要 C 的性能和 Ruby 的动态特性。 我们想要一门同调的语言,它既拥有 Lisp 那样真正的宏, 但又具有 Matlab 那样明显又熟悉的数学运算符。 我们希望这门语言可以像 Python 一样用于常规编程,像 R 一样容易地用于统计领域,像 Perl 一样自然地处理字符串,像 Matlab 一样拥有强大的线性代数系统,像 Shell 一样能够擅长组合程序。 这门语言要简单易学,但又能打动最认真的极客。 我们希望它可交互,同时希望它是编译的。
大多数用户都被 Julia 的 优越速度 所吸引。 毕竟,Julia 可是著名独家俱乐部 petaflop 的成员。 petaflop 俱乐部 的组成成员都是一些峰值运算速度超过 千万亿次每秒 的编程语言。 现在只有 C,C++,Fortran,和 Julia 属于 petaflop 俱乐部。
但是,速度不是 Julia 的全部。 Julia 的一些特性还包括易用性、 Unicode 支持 和 代码共享的便捷性。 本节将讨论这些所有的特性,不过目前先来关注 Julia 的代码共享特性。
Julia 软件包的生态非常独特。 它不仅允许共享代码,也允许共享用户自定义的类型。 例如,Python 的 pandas 使用自带的 Datetime 类型来处理日期。 同时, R tidyverse 的 lubridate 包也使用自定义的 datetime 类型来处理日期。 Julia 不需要上述任何一种类型, 因为其标准库已准备好了所有的日期工具。 这意味其他包不需要担心日期处理。 其他包仅需要为 Julia DateTime 类型扩展新功能,即定义新函数但不需要定义新类型。 Julia Dates 模块可以实现许多令人惊叹的功能,但目前讨论它有些超前。 于是让我们来讨论一些 Julia 的其他特性。
2.3.1 Julia VS 其他编程语言
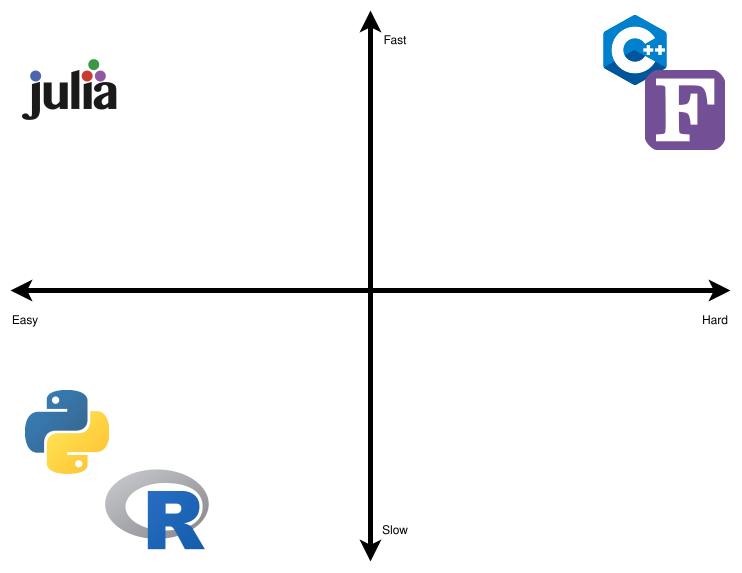
图 2 给出了非常个性化的分类,它将主流的开源科学计算编程语言分在一张 2x2 图中, 该图具有两个轴: Slow-Fast(慢-快) 和 Easy-Hard(简单-困难)。 我们省略了闭源语言,因为允许其他人运行你的代码以及检查源代码中的问题会具有许多好处。
我们把 C++ 和 FORTRAN 放在 困难-快 象限。 作为需要编译、类型检查和其他专业管理的静态语言,它们真的很难学习,原型代码也编写很缓慢。 好处是它们都是 非常快的 语言。
R 和 Python 放在 简单-慢 象限。 它们是不需要编译的动态语言,在运行时执行。 因此,它们很容易学习,能够快速创建原型代码。 当然,这会导致共同的缺点: 它们都是 非常慢的 语言。
Julia 是唯一一门在 简单-快 象限的语言。 我们知道任何其他严格的语言都不会想变得困难且缓慢,所以此象限为空。
Julia 很快! 特别快! 它起初就为速度而设计。 而这通过多重派发实现。 基本上,这个想法能够生成非常高效的 LLVM10 代码。 LLVM 代码,也称为 LLVM 指令,它非常靠近底层,即非常接近计算机执行的实际操作。 所以,本质上, Julia 会将你可读性好的手写代码转换为 LLVM 机器码。虽然 LLVM 机器码对于人类来说很难阅读,但对于计算机来说很容易。 例如,如果你定义了一个接收单个参数的函数并向该函数传递整数,然后 Julia 会创建一个 专门的 MethodInstance。 下次你再向该函数传递整数时,Julia 将会查找之前创建的 MethodInstance,并引用其执行操作。 一个很棒的 技巧是,可以在调用函数的嵌套函数中使用它。 例如,如果向函数 f 传递了某些数据类型,而 f 又调用了函数 g,同时传递给 g 的数据类型都是相同且已知的,那么生成函数 g 就会硬编码到 f 中! 这意味着 Julia 不再需要查找 MethodInstances,此时代码就会运行地非常快。 此处需要权衡的是,在某些情况下,早期关于硬编码 MethodInstances 的假设可能是无效的。 然后需要重新创建硬编码的 MethodInstances。 因此,权衡也需包括花时间推断哪些能够硬编码,而哪些不能。 这也解释了为什么 Julia 代码在第一次执行前通常要花费较长的时间: Julia 在背后优化代码。
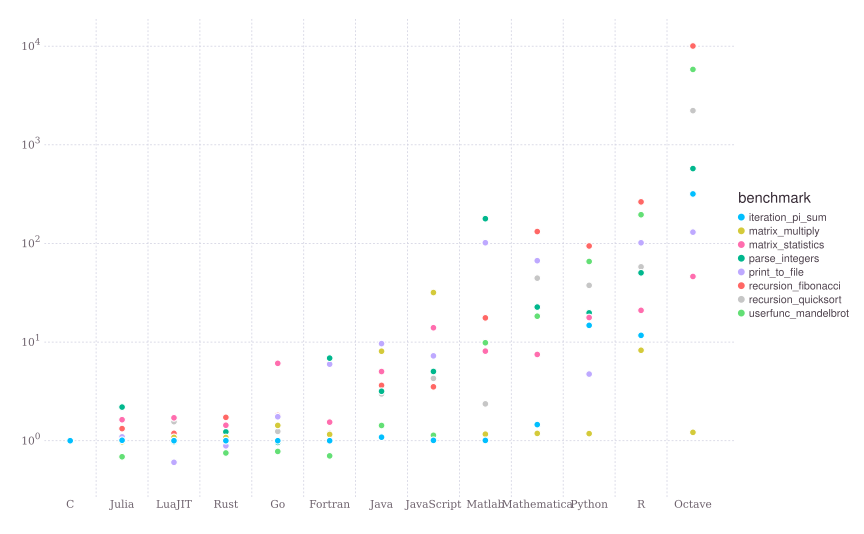
编译器接着做它最擅长的事情:优化机器码11。 你可以在 Julia 网站上找到 Julia 和其他语言的 benchmarks 。 图 3 取自于 Julia 网站的 benchmarks 节12。 如你所见, Julia 是相当 快的。
我们非常信任 Julia。 否则,我们不会写这本书。 我们认为, Julia 是 科学计算和科学数据分析的未来。 它使得用户可以通过简单的语法开发快速且强大的代码。 研究人员通常使用一种简单但缓慢的语言开发原型代码。 一旦确定代码正常运行且实现其目标,然后就会开始将当前的代码转换为一门快速但困难的编程语言。 这就是“两语言问题”,接下来将讨论它。
2.3.2 两语言问题
“两语言问题” 是科学计算中的典型问题。通常研究人员想要设计一种算法或方案来解决手头的问题或分析。 一般地,解决方案的原型代码都采用容易编程的语言(像 Python 或 R)。 如果原型能够正常工作,那么研究人员就会使用不易编写原型但快速的语言(C++ 或 FORTRAN)重新实现。 因此,开发解决方案的过程涉及了两种语言。 一种语言易于编写原型代码并不适合方案实现 (通常由于缓慢的速度)。 而另一种语言并不易于编写原型代码,但由于非常快,所以适合方案实现。 Julia 能够避免此类情形,因为 开发原型(易编程)和方案实现(速度快)将采用相同的语言。
另外, Julia 允许使用 Unicode 字符作为变量或参数。 这意味着不再使用 sigma 或 sigma_i,而是像数学记号那样使用 \(σ\) 或 \(σᵢ\) 。 当查看算法代码或数学方程时,你会看到几乎相同的符号和术语。 我们将这种强大的特性称为 “代码和数学关系的一对一”。
我们认为,Alan Edelman,Julia 创始人之一,在一次TEDx Talk (TEDx Talks, 2020) 中对 “两语言问题” 和 “代码和数学关系的一对一” 作出了最好的描述。
2.3.3 多重派发
多重派发(multiple dispatch)是一种强大的特性,它使得能够扩展现有的函数或为新类型自定义复杂行为。 假设想要定义两种 struct 来表示不同的动物:
abstract type Animal end
struct Fox <: Animal
weight::Float64
end
struct Chicken <: Animal
weight::Float64
end这表明此处定义了动物类型 Fox 和 Chicken。 然后生成名为 Fiona 的 Fox 和名为 Big Bird 的 Chicken。
fiona = Fox(4.2)
big_bird = Chicken(2.9)为了知道他们的重量之和,编写如下的函数:
combined_weight(A1::Animal, A2::Animal) = A1.weight + A2.weightcombined_weight (generic function with 1 method)然后还想知道它们能否相处得好。 采用条件语句实现:
function naive_trouble(A::Animal, B::Animal)
if A isa Fox && B isa Chicken
return true
elseif A isa Chicken && B isa Fox
return true
elseif A isa Chicken && B isa Chicken
return false
end
endnaive_trouble (generic function with 1 method)现在,看看 Fiona 和 Big Bird 待在一起是否会产生麻烦:
naive_trouble(fiona, big_bird)true好的,看起来不错。 编写 naive_trouble 函数已经足够简单了。然而,使用多重派发编写 trouble 函数还可以带来新的优势。按照如下方式创建函数:
trouble(F::Fox, C::Chicken) = true
trouble(C::Chicken, F::Fox) = true
trouble(C1::Chicken, C2::Chicken) = falsetrouble (generic function with 3 methods)定义这些方法后,trouble 会得到与 naive_trouble 相同的结果。 例如:
trouble(fiona, big_bird)true把 Big Bird 和另外一只小鸡 Dora 放在一起也是可以的。
dora = Chicken(2.2)
trouble(dora, big_bird)false所以在本例中,多重派发的优势就是可以仅声明类型,然后由 Julia 去为类型找到正确的函数方法。 若是在嵌套函数中使用多重派发则更是如此,Julia 编译器实际上会自动优化函数调用。 例如,函数如下:
function trouble(A::Fox, B::Chicken, C::Chicken)
return trouble(A, B) || trouble(B, C) || trouble(C, A)
end根据上下文,Julia 会将其优化为:
function trouble(A::Fox, B::Chicken, C::Chicken)
return true || false || true
end因为编译器 知道 A 是 Fox, B 是 Chicken ,所以方法替换为 trouble(F::Fox, C::Chicken)。 trouble(C1::Chicken, C2::Chicken) 同理。 然后,编译器进一步优化:
function trouble(A::Fox, B::Chicken, C::Chicken)
return true
end此外,多重派发还使比较已存在的动物和新的动物 Zebra 成为可能。 可以在其他包中定义 Zebra :
struct Zebra <: Animal
weight::Float64
end然后定义与现有动物的交互:
trouble(F::Fox, Z::Zebra) = false
trouble(Z::Zebra, F::Fox) = false
trouble(C::Chicken, Z::Zebra) = false
trouble(Z::Zebra, F::Fox) = falsetrouble (generic function with 6 methods)现在可查看 Marty(Zebra 动物)是否能与 Big Bird 和谐相处:
marty = Zebra(412)
trouble(big_bird, marty)false更好的是,不需额外定义任何函数即可计算 Zebra 和其他动物的重量之和:
combined_weight(big_bird, marty)414.9因此,总而言之,即使在编写代码时只考虑了 Fox 和 Chicken,但它也能用于 从未见过的 类型! 在实践中,这意味着重用其他 Julia 项目的代码会非常容易。
如果你和我们一样对多重派发感到兴奋,那么可以了解下面这些深入的例子。 第一个例子是,Storopoli (2021) 关于 one-hot 向量的快速而优雅的实现 。 第二个例子是,Tanmay Bakshi YouTube 频道 对 Christopher Rackauckas 的采访 (查看时间 35:07 ) (tanmay bakshi, 2021)。 Chris 提到, 在他开发和维护 DifferentialEquations.jl 包时,一名用户报告问题说:他基于 GPU 构造的 ODE 求解器并不能正常工作。 Chris 对这个请求感到非常惊讶,因为他从来没有期望能够将 GPU 计算与求解边界值问题结合起来。 他甚至更惊讶地发现,用户犯了一个小错误,但一切正常。 这些大多数优点都来自于多重派发和高可用的代码 / 类型共享。
总的来说,我们认为多重派发的最好解释来自于 Julia 创始人 Stefan Karpinski 在 JuliaCon 2019 的演讲。
8. 有时甚至快于C。↩︎
9. 译者注:这段话的翻译参考了 InfoQ 的文章 “再见 Python,你好 Julia!”。↩︎
10. LLVM 是 Low Level Virtual Mchine 的缩写,你可以在LLVM 网站(http://llvm.org)找到更多信息。↩︎
11. 如果你想了解更多关于 Julia 如何设计的内容,你绝对需要看 Bezanson et al. (2017) 。↩︎
12. 请注意上述的 Julia 结果不包含编译时间。↩︎